PROBABLY PRIVATE
Issue # 15: Privacy attacks on AI/ML systems



Hello Privateers,
I hope your summer is off to a great start -- I spent some time swimming in the Mediterranean. Hope you take time to enjoy something you love.
Now it's time to dive back into AI/ML memorization with the initial article of the solutions/approaches for addressing memorization. I'll be releasing about 2 articles a month for the next few weeks, so stay tuned to learn about ways to address the memorization problem.
Before you can address any problem, you need to be able to define it in a way you can evaluate, measure and learn from -- in this issue, you'll review two major attack vectors that exploit AI/ML memorization.
A membership inference attack (MIA) attempts to infer if a person (or particular example) was in the training data or not. It was first named by Shokri et al.'s work in 2016, where the researchers were able to determine which examples were members (in the training data) and which ones were not.
The original attack used a system of shadow models which mimic the target model. The outputs of these shadow models are used to train a model that can discriminate between in-training and out-of-training examples based on the model outputs or by using the model outputs to calculate the loss compared to the true labels.
Why does this work? If a model memorizes a particular example, it should return large confidence and accuracy on that data point compared to data points it hasn't seen. If these examples are infrequent or rare (i.e. in the long tail), then these examples are overexposed compared to other examples, which can "hide in the crowd". As you already learned, larger and more accurate models produce this problem more often than smaller and less accurate models.
Finding memorized examples via MIAs can be done quite reliably, especially in an improved version of the attack from Carlini et al., called the Likelihood Ratio Attack (LiRA). This updated version of MIA is specifically designed to minimize false positives (i.e. alerting that something is a member when it is not).
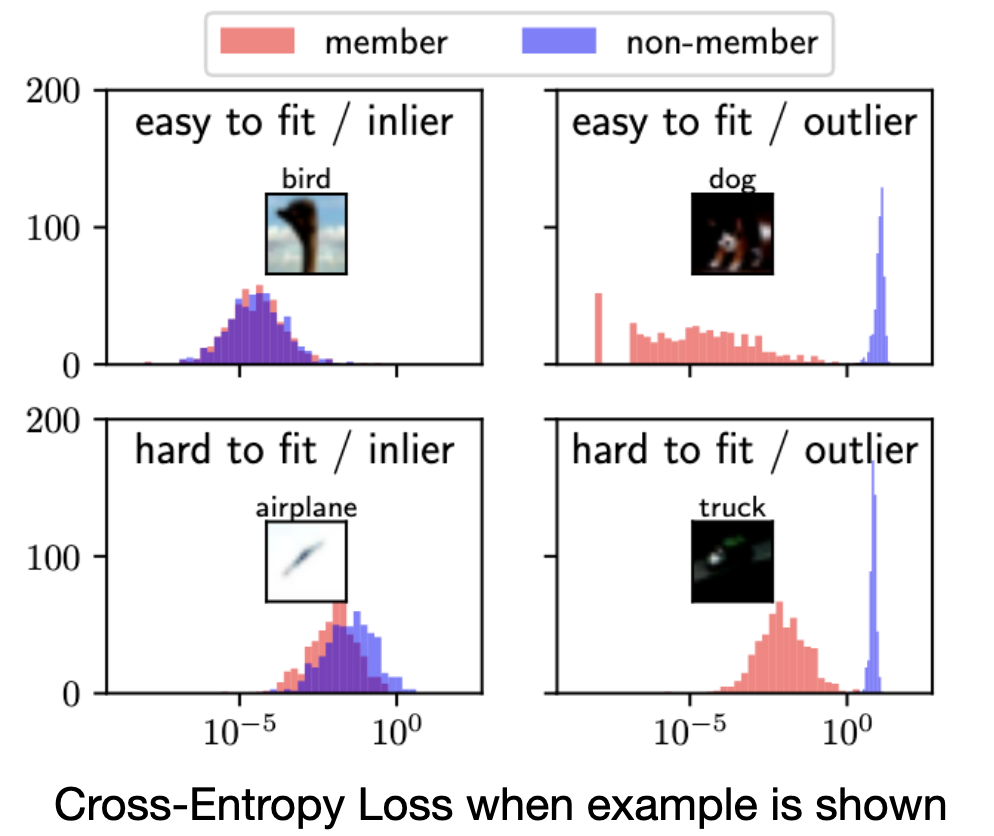
Carlini et al. produced the image shown above, which demonstrates the task at hand. Your job as the attacker is to separate the distributions. In this example attack, you use scaled cross-entropy loss, which you can calculate with the the target model prediction (so long as you know or can guess what the true sequence or label should be).
Why are MIAs privacy attacks? It relates to the same principles as differential privacy. If I know you are in the training data, I might also learn something new about you from that very fact that you are there. For example, there are models are used to classify diseases or are trained on a particular subpopulation (like people of a particular income group). If I know those things about the model and learn you are in the training data, I also learn something about your disease or income status.
Additionally, knowing you are in the training data can inspire me to perform another type of attack...
Want to test out your own LiRA? Tensorflow Privacy has some example code and instructions.
If you can determine that someone's data is in the training data, you might want to leverage that knowledge to extract as much information about them as possible from the model. Or you might just be innocently querying a model (via prompt or another interface) and end up learning more than you expected.
Exfiltration attacks allow the attacker to extract training data, either in complete, in partial or paraphrased form. This might mean accidentally learning personal text data, like social security numbers, credit card numbers and home addresses which can then be extracted either by querying the model itself or via a targeted attack.
There are variants of these attacks that use both "white box" (i.e. direct probing the model while also being able to view the model's internal state) and "black box" (i.e. API access) methods.

The above images are not exact duplicates but are clearly near-duplicates. For each pair, the left images are from the training data, and the right images are generated by prompting Midjourney with the training data caption. This research from Webster (2023) revealed efficient and accurate ways to reconstruct training data from diffusion models.
But this threat also extends to innocuous prompts that inadvertently expose sensitive information or paraphrases confidential or copyright information without attribution. For example, after the launch of ChatGPT-3.5, Amazon's legal department found text snippets of internal corporate secrets in the chat model's responses.
Want to learn more about these attacks? Check out the full article and YouTube video. These attacks are also covered in my O'Reilly book, which is now available in 3 languages 🇬🇧 🇩🇪 🇵🇱.
Interested in trying out these attacks on your own models? Want advice on how to do so?
I'm offering free consultations on Mondays to discuss if a training, workshop or long or short-term advisory can jumpstart or accelerate AI/ML privacy/security work in your organization. If you are interested in a different engagement model, I'd be happy to discuss.
I'll be offering some free webinars and workshops later this summer on topics like Memorization, Adversarial Machine Learning (aka AI/ML security) and integrating privacy and security testing into your AI product lifecycle. If you have a burning question on these topics, let me know it beforehand so I can make sure to integrate FAQs. Until next time...
 With Love and Privacy, kjam
With Love and Privacy, kjam