PROBABLY PRIVATE
Issue # 17: Machine Unlearning: What is it?



Hello privateers,
I've seen some hefty discussion on AI memorization across social media channels, and today I'm bringing you the next in my article series on the issue. If you're just now joining, you might want to binge read the previous articles or listen to me TLDR chat about it on YouTube.
Machine unlearning is widely cited as the supreme solution to AI memorization problems (when people aren't talking about guardrails). But, what exactly is machine unlearning?
Machine unlearning is essentially the ability to selectively remove information from a model. It would solve many problems in today's largest AI/ML models if you could do it efficiently and effectively. If it works, unlearning (or "targetted forgetting") could remove security and privacy violations and unethical content from models.
Studying how models "forget" isn't a new phenomenon. Prior forgetting research wanted to ensure models don't forget necessary information or help explain when, how and why models forget. Other forgetting research studied it to figure out what is essential for learning.
Machine unlearning targets specific information by collecting examples to forget into a forget dataset and then running an unlearning process.
But how do you know that you've unlearned something? There are competing definitions with different metrics, measurements and vibes. Let's review the most common:
If you investigate the larger field of forgetting, however, you understand that the problem is not as simple as it might seem at first glance.
Maini et al. (2022) summarized a meta-perspective in the following diagram.
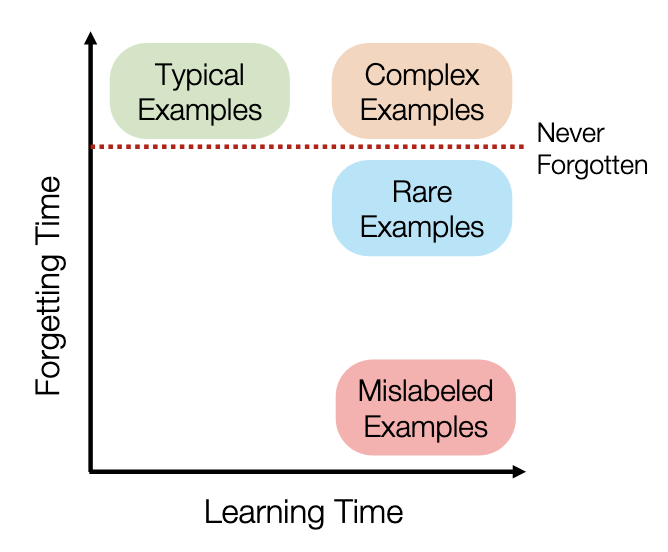
The ability to forget or unlearn a particular example or population/class is directly linked to things like the typical vs atypical data, and factors like data and task complexity. Meaning: some data is harder to forget and complex tasks require more memorization.
And it goes beyond that. Tirumala et al (2022) demonstrated a forgetting baseline, where models of a particular size were never able to forget a subset of examples. The larger the model, the harder it is to unlearn or forget.
This relates to already known concepts in information and learning theory. If certain information is essential to complete a task (either because of data or task complexity), then it must be learned and stored.
Some of that information is more general/typical and doesn't result in problematic memorization. This falls under paradigms of "model generalization." Whereas other information is so surprising, rare, interesting that these examples are stored in the model and are much harder to forget or unlearn.
So, how can you define unlearning based on what is known about forgetting? Well, you can account for factors that contribute to memorization, forgetting and learning, which means thinking about information, dataset representation, model size, and task complexity.
With these in mind, the field can work towards standardizing several definitions that allow practitioners to make informed decisions about which definition matches their expectation, and how to reach that definition given the available methods for unlearning today. More on those methods in the next article!
There's a much deeper article on forgetting research and unlearning definitions on my blog. You can also check out my YouTube videos on forgetting, information theory and privacy and unlearning definitions (will post next week) -- which are just video takes on the longer blog post.
In my interview with Tariq Yusuf as part of my Privacy Engineering series, he asks privacy engineers and professionals to reflect on our role in the organization and the larger role of our work in society.
On the chilling effect: "I'm Muslim and a brown looking person post 9/11 and that experience growing up, there was a lot of self censoring and things that I didn't participate in or I did not say because of this fear of surveillance and the entire institutions that were built to surveil people like me. Understanding firsthand that chilling effect... and how it can limit otherwise positive behaviors in an open society. We want to make sure that we don't replicate that in other places."
On Privacy Engineering as Applied Ethics: "I'd like to see privacy engineering as the home for applied technology ethics. Because privacy engineering by definition is putting a limit on what the business can do. That is the goal of ethics as a whole. And a lot of what we do; it's very much a golden rule approach where I wouldn't want this thing done to me. So why should we do it to other users?
I would like to see this evolve into how can we actually take the conversations from AI ethicists, from policymakers, and from sociologists and apply this in a way that says, here's how we can build a proactive picture of what technology looks like and the type of technology that we want to have as a society."
On privacy's role in organizational power structures: "If your privacy organization is not empowered to advocate for the right thing, it can limit the results.
When I'm having a conversation with a product team, I have to think, how much do I want to push on this? ... If it's going to be escalated up to management, which perspective is management likely to take? Is my management willing to back up the decisions that I make?
If you are a manager or a director in privacy, you're going to get escalated to a lot more than if you're in other organizations, even security, I would argue, because your organization as a whole is pushing against the power dynamics of the organization."
Great stuff to chew on.
Check out the entire conversation on YouTube and follow his work on Mastodon, BlueSky and LinkedIn.
It seems that every week someone releases a brand new AI governance (or Risk/Security/etc) Taxonomy/Guideline/etc. Although I'm generally a fan of standardization, the rate of release and the usefulness of the ever increasing number of taxonomies is overwhelming.
I wrote a short post with my tips for governance and risk professionals who must determine how to proceed given the impending AI act regulations.
It focuses on actions that make sense for the actual AI/data use at your organization. Starts small and builds via learning and experience. And creates processes and infrastructure as starting points instead of trying to do Everything Everywhere All at Once.
If you're already setting up these processes and you've published anything I can share further, send it my way!
I'm always keen to hear your thoughts, feedback and questions from this issue. Just hit reply and let me know.
If you enjoyed this newsletter and want to spread the word, tell someone new to subscribe. I also have implemented an RSS feed for my blog, if you want to hear from me more often.
In the next issue, you'll learn about how different approaches to implement machine unlearning and explore attacks on unlearning methods. Until then...
 With Love and Privacy, kjam
With Love and Privacy, kjam