PROBABLY PRIVATE
Issue # 20: Differential Privacy in Deep Learning and AI



Hello privateers,
It's November and I'm already drinking Christmas Roast coffee. I have no shame since I'll be in Australia and New Zealand in December and am already feeling a bit sad that I'm missing my favorite season in Germany. Real question: can I find a Weihnachtsmarkt in Melbourne?
In the past few newsletters, you've been exploring machine unlearning as a popular solution on how to quick-fix memorization in AI/ML systems. But it's a bit trickier and more expensive than originally thought.
This month you'll dive into differential privacy in AI/ML systems. If you've read my book, you already know some of this, but a review never hurts!
My favorite definition of differential privacy comes from Desfontaines and Pejó's 2022 paper (brackets are added for this particular scenario):
An attacker with perfect background knowledge (B) and unbounded computation power (C) is unable (R) to distinguish (F) anything about an individual (N) [when querying a machine learning model], uniformly across users (V) [whose data was in the training dataset] even in the worst-case scenario (Q)
Differential privacy is a fairly strict and rigorous definition of privacy standards. But you can tune variables (shown in letters above) to make your definition stronger or weaker based on use case and context-specific privacy requirements.
Ideally when doing machine learning, you are learning from many persons not from one individual; therefore, differential privacy is a natural fit if you want to make sure that you learn from a group and not from any one specific person.
It's been widely shown in research and practice that differential privacy significantly reduces memorization. Proper usage reduces both the chance that a membership inference attack (MIA) will succeed and often removes the chance of training data exfiltration entirely.
How does differential privacy work in ML/AI? The training process is changed, and yes, there are already deep learning OSS libraries that do this!
Here's a step-by-step rundown of the DP-SGD process:
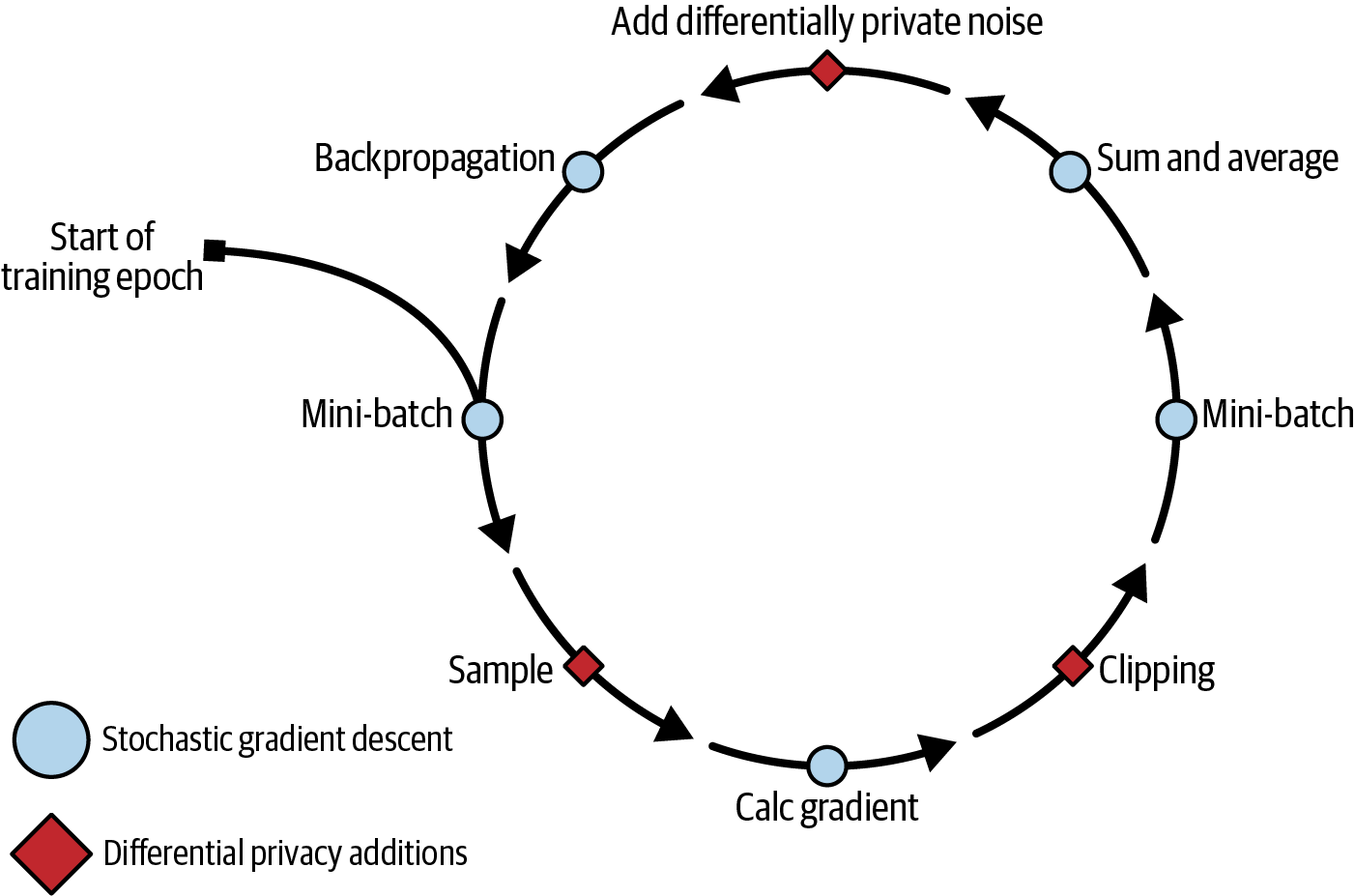
In the graphic above from my book Practical Data Privacy, you see a training epoch that starts with a mini-batch, which is a sample of the training data used in a training round.
The mini-batch is broken down per example (i.e. assumed per user) and the gradient is calculated by taking the derivative of the loss function with respect to the current model weights. Think of this gradient as "how much does this example change the model".
Then, each gradient is clipped to provide some protection for large changes and aggregated back into the mini-batch with the other gradients: here by a sum and then an average.
Gaussian noise is scaled according to the mini-batch average and the privacy parameters you choose (like the variables in the definition above) and then added to the result. The final gradient updates can now be used to change model weights and restart the process until, after many mini-batches, the training finishes.
Choosing the noise carefully is an interesting avenue of research. Getting this choice right for machine learning systems means being able to learn effectively while also providing the same guarantees for individual privacy. As deep learning grew more popular, so did more precise definitions of the noise required in deep learning systems.
From practice and research, Rényi differential privacy (RDP) has become a popular and widely implemented definition for DP-SGD. RDP provides an improved calculation of the bounds in the Gaussian noise distribution that: (a) simplifies the correct choice of privacy parameters and (b) allows a "tighter composition" so you can add less noise to get the same guarantees.
There's heaps to learn if you tried DP-training once and "it didn't work". I detail all the tips and tricks you can use to ensure your differentially private training goes well. Short summary: focus on batch size, sampling and learning rate adjustments!
And in case you needed another reason to try DP-training, the latest DeepMind research and experimentation shows there are optimal scaling budgets, providing calculations you can run to find batch size, compute requirements, epsilon values and dataset size together.
If you're already running Local AI, DeepMind released VaultGemma-1B on HuggingFace/Kaggle. You can run the differentially private trained LLM locally via vLLM or launch it in a supported cloud like Colab. Let's hope we get an ollama integration soon so we can easily choose differentially private LLMs. 🤞🏻
I see many security teams overwhelmed by governing security risk in AI systems with no additional support. I made a short YouTube video on what I would do if I was tasked with implementing a security strategy for AI/ML use at an organization. Here's my guidebook:
Understand Usage: With your product hat on, go talk with teams to understand what they are using AI for and how. What do they want to achieve? If deploying AI/ML for customer or client use, how should the customer use it?
Update Vendor Reviews: Sit with interdisciplinary risk stakeholders (privacy, compliance, audit, engineering) and update the current vendor review process. What additional questions and documentation do you want to outline? Here's a few suggestions: What guardrails are in use? What privacy and security testing has the model completed? Is there a model card available?
Start Testing: Start small with a few security concerns uncovered by your use case investigation. For example, if you are deploying public-facing AI, you might want to test prompt injection attacks, access restrictions and DDOS. If you are deploying an internal system with access to organization-wide data, you might try accessing data you shouldn't be able to find. Build out some basic use-case-informed tests and start building tooling around AI endpoints and integegration testing (both internal and third-party integrations).
Develop Minimum Security Requirements: Now that you have some testing and understand your primary use cases, you can develop minimum security requirements. These will be use case specific at first and later become guidelines for organization-wide deployment. For example, maybe a vendor must pass 60% of your security tests to be integrated into common workflows. Or maybe if a vendor doesn't meet this threshold, the team that wants to use it must install guardrails. By establishing a "lower bound" and assigning actions, you are increasing cross-organization ownership and responsibility for security related to AI workflows.
Foster a Community of Practice: You won't be able to do it alone, even if you try. Building a community of practice around AI/ML security means expanding the task from a small subset of security professionals to everyone at the organization who might be curious and motivated. Celebrate with hack days! Teach each other new attacks and defenses from research. Share what worked and what failed. Create communal ownership and agency with this bottoms-up approach. You can thank me later for how much you learn in doing so. :)
If you are working on AI/ML security strategy, what steps did I miss that you're taking? Any suggestions or thoughts?
This year I've had a chance to work with small and large teams on privacy and security in AI/ML via my company, kjamistan.
I'm actively planning engagements for next year. Want to work with me? I can help:
I charge a day rate, but am happy to discuss what formats work for you and your organization. I will also offer masterclasses (this time in one in Germany!) and an online course in 2026, so stay tuned.
Final Note: The private email provider RunBox I use to send this email has a promotion right now for 25% off. I am not paid to say this, I just really like their service. They are privacy-first, based in Norway and built on sustainable energy. Their webmail interface is old-school; but I use an email client and I'm really happy with them.
It's a pleasure to read from you; either by a quick reply or a postcard or letter to my PO Box:
Postfach 2 12 67 10124 Berlin Germany
Until next time!
 With Love and Privacy, kjam
With Love and Privacy, kjam