PROBABLY PRIVATE
Issue # 16: Guardrails: What are they? Can they help with privacy issues?



Hello privateers,
How are you doing? Are you getting good rest? Enjoying some time outside? Spending time with your communities to refresh? I hope so, if not, here's a gentle and kind nudge. :)
I'm really excited to be speaking at an IAPP Munich KnowledgeNet event this week -- helping privacy professionals dive deeper into the technical realities of AI privacy. And yesterday I was on Hugo Bowne-Anderson's podcast with Joe Reis (YouTube Link) talking about decentralized AI.
In this issue, you'll dive into AI guardrails -- a term that's used to describe several different technologies. You'll look at the three main approaches and evaluate what they can and cannot address with regards to privacy.
Guardrails are used in order to protect against potential undesired behavior from any AI system, although commonly used when using LLMs or other generative AI. This term first emerged in 2023, the year ChatGPT launched their open consumer service -- which is no surprise. The initial versions had plenty of security and privacy holes, which eventually led many AI companies to install guardrails as a way to mitigate the privacy problems, security issues and questionable content (i.e. ethical issues).
The easiest and most commonly used set of initial guardrails for companies deploying AI systems is putting software around the system and using it to intervene if undesired input or output appears.
How does it work? Let's take a look at a system diagram.

In the above figure, the chat messages come in from a user via an API call to software that processes the input. As you learned in exploring the design of a machine learning system, this text and additional input (like photos) will be prepared for the machine learning input.
The AI model will process that input and calculate a response. Often there is software around this step that requests multiple possible responses. Depending on the design, the model might return the beginning of a response while the system continues calculating the next part of the response. Remember: the model will use its own response as part of the input to continue calculating the next word(s).
Sometimes the response is fully formed before being sent to the user, but sometimes the response can start before the final text is formulated. Either way, this response usually goes through another batch of software filters on its way back to the original user.
So, can this address privacy problems? Only in the most brittle sense. For example, companies have used it to block answering on a given name by providing a generic response, or used it to stop from verbatim repeating text or code found online. But, if you know anything about hash-based filters, this can miss matches that have small changes.
In fact, Ippolito et al. proved just this by asking Copilot to generate copyrighted code that is normally blocked by such a filter and were able to bypass it by changing the variable names to French.
So, in a pinch these filters can work -- but only for a very narrow definition of privacy problems. They, like many input/output filters are by-design quite brittle and don't scale as well because you'll have to design these software filters to "fit" around a large non-deterministic system -- a difficult, if not impossible task!
You can read more about these types of guardrails and their application on my blog.
The second main group of guardrails are what I call external algorithmic guardrails. Let's define them via a few key points:
They use algorithmic means to discover input/output which violates whatever rules the user has set up.
They are not directly in the model that is processing the sequence, hence they are external to the model.
This usually means that either the input, output or both are tested by another machine learning model. This can be a model trained specifically on the task of identifying questionable or undesired content, such as Llama-Guard. Or it can be another LLM or other large model that is used with the instructions to identify potentially risky content, which is often referred to as "LLM as a judge".
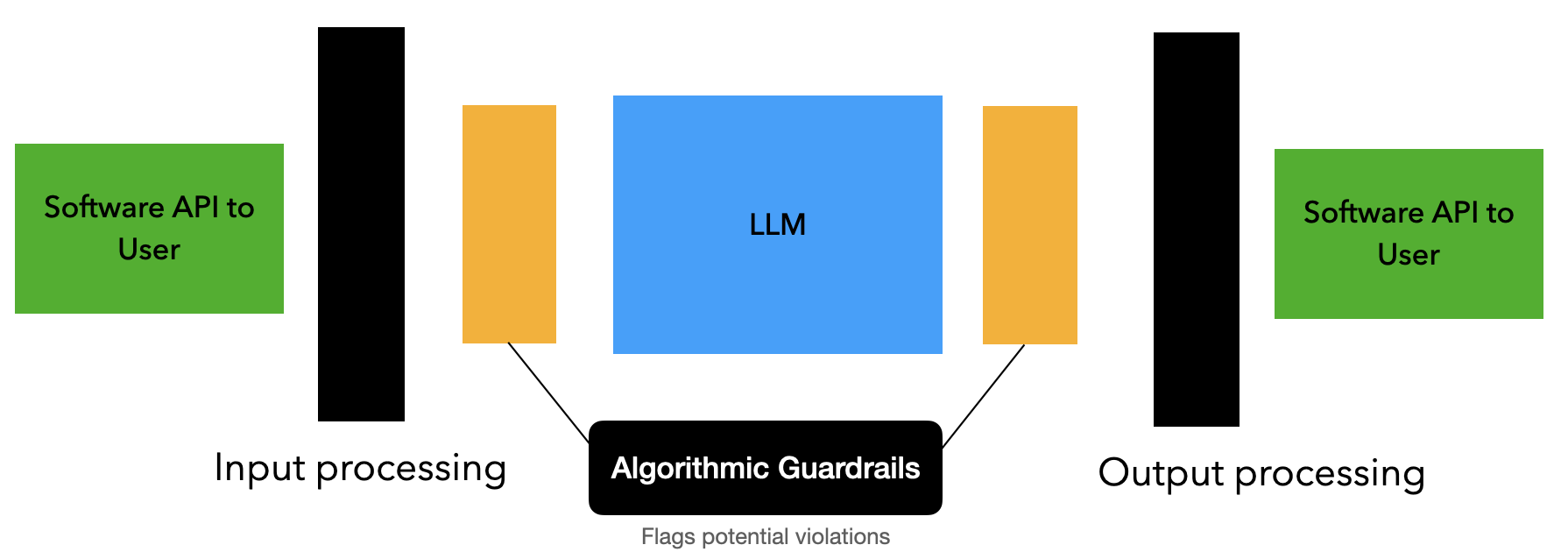
In these cases, this often doesn't completely prevent the possibility of bypassing these algorithmic guardrails but it indeed reduces the likelihood that questionable content will be released. Therefore, like any good security mechanism, it increases the attacker's cost of successfully evoking a risky response. By making it more difficult to attack, both because you now need to attack two machine learning models instead of one, and by catching easy-to-spot attempts, it certainly provides better protection than software alone.
Can it address difficult privacy concerns, like releasing memorized information about a person likely shared out of context? Probably not, because that would require a different type of system check -- one that could both understand the likelihood that some training data was memorized and another that can determine the closeness of the output to the training data. Ideally avoiding these mistakes happen at training time and not at inference, so that undesired memorization simply doesn't happen.
In fact, that's a large part of the overall privacy and security problems in generative AI. Ideally they wouldn't be trained on a bunch of internet content of murky origin and quality. If we didn't poison AI models from the start, we wouldn't have to worry about them encouraging someone to commit suicide or spreading misinformation and conspiracy theories.
This leads us to the final type of guardrail, which are built into models with fine-tuning.
The final option is implementing guardrails in the model itself, usually by fine-tuning guardrails near the end of the model training. This happens anyways during training that takes human preferences into account.
For example, reinforcement learning with human feedback and direct preference optimization are two common methods to take a base language model and make it into an instruction and/or chat-based model. Both of these methods require having an additional dataset that has been labeled or improved by humans to make the content more aligned with both how humans want models to help them and also tends to shift the language away from internet trash.
If specific guardrails need to be trained in addition, these can also be added. Sometimes these fine-tuning steps are called alignment.
Unfortunately this fine-tuning and/or extended training doesn't immediately reverse or make that information in the network inaccessible, it just makes it less likely to show up. This is exactly why there are entire areas of research and practice in "jumping guardrails" or "jailbreaking", because the information from the base model still allows for the model to produce undesired output.
Another way to approach this at scale would be to implement quality checks and pipelines in preprocessing that utilize either data cleaning (i.e. replacement of parts of text that trigger an alert via your other guardrails) or simply delete parts of the training data that should be avoided. Unfortunately most model providers don't take this step, which is why we still have models that are full of internet troll behavior.
Ideally the field would focus on finding content partnerships or empowering content companies or providers (like publishers, journalists, artists, professors, etc) to create more trustworthy and less trashy base language models. Obviously it would be useful if big tech companies compensated these people for their work and knowledge and built models (or software around these models) that could find the original citations and attribute information to creators.
Building enthusiastic consent models, where people really want to contribute their content and where they could potentially be cited or compensated for their content, would be a step toward a safer and more trustworthy model landscape, but also one that better respects privacy and copyright.
You can read more about the second two types of guardrails on my blog or watch this newsletter as a YouTube video.
What's your experience been with regard to guardrails? What ideas do you have on addressing privacy issues more holistically?
If this newsletter was useful for you, consider forwarding it to someone so they can subscribe.
And don't forget, you can practice the concepts in this newsletter and my book at my upcoming masterclasses:
Want to host one of your own? Reach out and let's chat!
Until next time...
 With Love and Privacy, kjam
With Love and Privacy, kjam